GPU Interconnect: NVLink with NVSwitch, up to 600 GB/s per GPU connection
Interface: PCIe Gen4
Cooling: Typically integrated into complete server solutions
Consumption (W): 1500 W
Form Factor: SXM4
PCI Express: Generation 4.0, 2 GB/s per line, 16 lines
CUDA Technologies: CUDA stream processors
Output to the Monitor: None
Use Cases: AI training, HPC, data analytics, model parallelism, and more
1. Especificação Técnica necessária (Hardware)
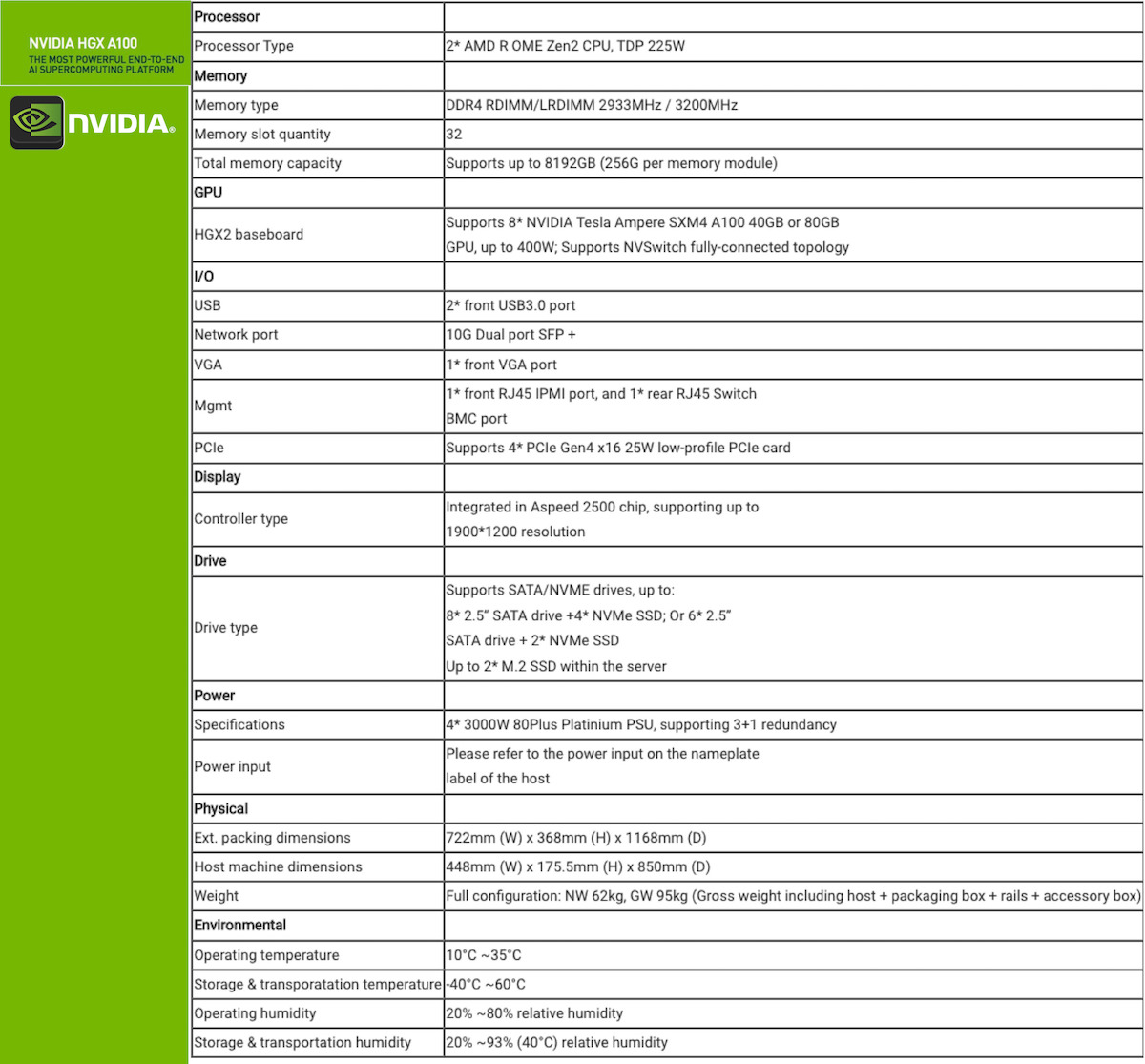
Quantidade de GPUs: 8x NVIDIA A100 Tensor Core.
Memória Total: 640 GB HBM2e (Confirme se é a versão de 80GB por GPU, e não a de 40GB).
Interface: SXM4 (Diferente da PCIe, esta é para encaixe direto na placa de base).
Interconectividade: NVLink de 3ª geração (600 GB/s de largura de banda entre as GPUs).
Resfriamento: Especificar se é Air-Cooled (Delta) com dissipadores passivos incluídos.
2. Condição e Procedência
Estado: Lacrado de Fábrica
Garantia é NVIDIA Enterprise Support (oficial): 5 anos
3. Requisitos de Infraestrutura
Muitos clientes compram a placa e descobrem que não têm onde ligar.
Chassi Compatível: Deve ser um servidor certificado para HGX
Energia: Requisito de fonte de alimentação (geralmente 4x 3000W em redundância).
Fluxo de Ar: Necessidade de ventiladores de alta pressão estática no rack.
4. Cronograma de Entrega e Logística
Prazo de entrega: cotado na data (considerando que é um item de importação/estoque limitado).
Seguro de Carga: Confirmamos que o envio possui seguro total contra danos ou extravio (essencial para um item de $65k+).
Impostos e Taxas: Os impostos de importação já estão incluídos no preço final.
5. Tabela de Comparação de Desempenho (Valor Agregado)
Tabela de Performance: HGX A100 vs. Gerações Anteriores
Esta tabela foca no Treinamento de IA (Deep Learning) e HPC (Computação de Alto Desempenho):
Métrica de Desempenho
Servidor Convencional (8x V100)
NVIDIA HGX A100 (8x GPUs)
Ganho de Velocidade
Treinamento de IA (TF32)
125 TFLOPS
2.500 TFLOPS (2.5 PFLOPS)
20x Mais Rápido
Inferência de IA (INT8)
500 TOPS
10.000 TOPS (10 PFLOPS)
20x Mais Rápido
HPC (FP64)
60 TFLOPS
156 TFLOPS
2.5x Mais Rápido
Largura de Banda (NVLink)
300 GB/s
600 GB/s
2x Mais Rápido
Por que o HGX A100 é tão superior?
Tensor Cores de 3ª Geração com TF32: A arquitetura A100 dinâmica o formato TF32, que permite processar IA com a precisão do FP32, mas com a velocidade de 20x superior encontrada em formatos mais simples. Isso significa que modelos que levam 20 dias para treinar agora levam apenas 1 dia [1.1, 1.3].
Tecnologia Multi-Instância GPU (MIG): Diferente das placas RTX ou V100, uma única GPU A100 pode ser dividida em até 7 instâncias isoladas. Em um HGX com 8 GPUs, seu cliente pode rodar até 56 cargas de trabalho simultâneas e independentes [1.1, 1.2].
Memória HBM2e de 640 GB: Com 2 TB/s de largura de banda de memória por GPU, o HGX A100 elimina o "gargalo" de dados, permitindo que modelos de linguagem gigantes (LLMs) carreguem e processem informações quase instantaneamente, algo impossível em placas RTX comuns [1.1, 1.2].
Em estoque no nosso parceiro, no entanto, os prazos de entrega podem ser de cerca de 8 a 12 semanas, independentemente, devido ao arquivamento da certificação EUS sobre os requisitos de exportação. Disponibilidade, preços e alocações podem flutuar diariamente. Todas as vendas são finais. Sem devoluções ou cancelamentos.
A SUPERCOMPUTAÇÃO DE IA DE PONTA A PONTA MAIS PODEROSA
Desempenho incrível em todas as cargas de trabalho
Especificamente criado para a convergência de simulação, análise de dados e IA
Grandes conjuntos de dados, tamanhos de modelos explosivos e simulações complexas exigem várias GPUs com interconexões extremamente rápidas.
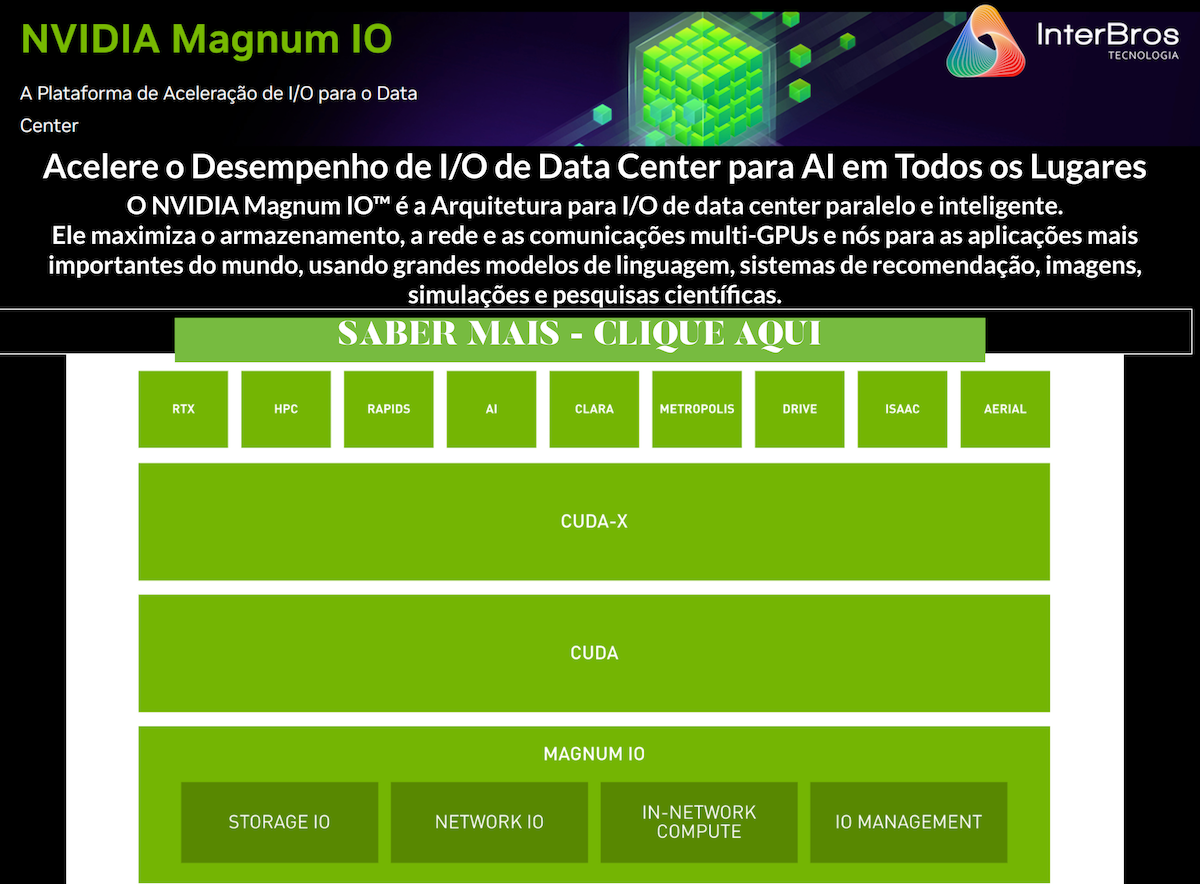
A plataforma NVIDIA HGX reúne todo o poder das GPUs NVIDIA, NVIDIA® NVLink®, rede NVIDIA Mellanox® InfiniBand® e uma pilha de software NVIDIA AI e HPC totalmente otimizada da NGC para fornecer o mais alto desempenho de aplicativo.
Com seu desempenho e flexibilidade de ponta a ponta, a NVIDIA HGX permite que pesquisadores e cientistas combinem simulação, análise de dados e IA para promover o progresso científico.
Com uma nova geração de GPUs A100 de 80 GB, uma única HGX A100 agora tem até 1,3 terabytes (TB) de memória de GPU e os primeiros 2 terabytes por segundo (TB/s) do mundo de largura de banda de memória, proporcionando aceleração sem precedentes para cargas de trabalho emergentes, alimentadas por tamanhos de modelos explosivos e conjuntos de dados massivos.
A terceira geração do NVIDIA NVLink cria uma única super GPU.
A escala de aplicativos em várias GPUs requer movimentação de dados extremamente rápida.
A terceira geração do NVIDIA NVLink na GPU NVIDIA A100 Tensor Core dobra a largura de banda direta da GPU para a GPU para 600 gigabytes por segundo (GB/s), quase 10 vezes maior que o PCIe Gen4.
A terceira geração do NVLink está disponível em servidores HGX A100 de quatro e oito GPUs dos principais fabricantes de computadores.
A segunda geração do NVIDIA NVSwitch impulsiona a computação de largura de banda total
O NVIDIA NVSwitch com tecnologia NVLink cria uma estrutura de rede unificada que permite que todo o nó funcione como uma única GPU gigantesca.
Os pesquisadores podem implantar modelos de escala sem precedentes e resolver os problemas de HPC mais complexos sem serem limitados pela capacidade de computação.
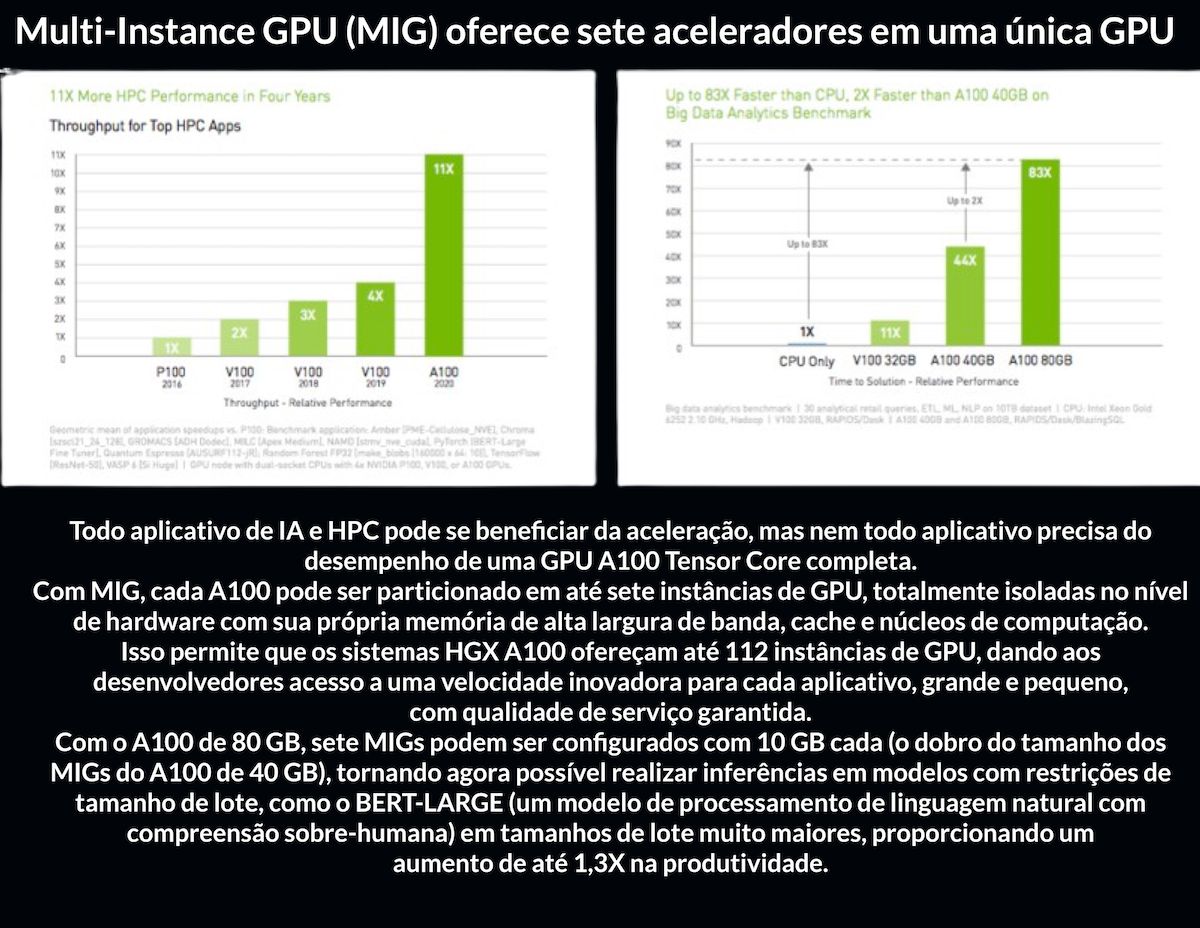
GPU multi-instância (MIG) oferece sete aceleradores em uma única GPU
Todo aplicativo de IA e HPC pode se beneficiar da aceleração, mas nem todo aplicativo precisa do desempenho de uma GPU A100 Tensor Core completa.
Com a MIG, cada A100 pode ser particionado em até sete instâncias de GPU, totalmente isoladas no nível de hardware com sua própria memória de alta largura de banda, cache e núcleos de computação.
Isso permite que os sistemas HGX A100 ofereçam até 112 instâncias de GPU, dando aos desenvolvedores acesso a uma velocidade inovadora para cada aplicativo, grande e pequeno, com qualidade de serviço garantida.
Com a A100 de 80 GB, sete MIGs podem ser configurados com 10 GB cada (o dobro do tamanho das MIGs A100 de 40 GB), tornando agora possível realizar inferência em modelos com restrições de tamanho de lote como BERT-LARGE (um modelo de processamento de linguagem natural com compreensão sobre-humana) em tamanhos de lote muito maiores, proporcionando um aumento de até 1,3X na taxa de transferência.
Os núcleos tensores de terceira geração redefinem o futuro da IA e HPC
Introduzida pela primeira vez na arquitetura NVIDIA Volta, a tecnologia NVIDIA Tensor Core reduziu os tempos de treinamento de IA de semanas para horas e forneceu uma aceleração massiva para operações de inferência.
A terceira geração de núcleos tensores na arquitetura NVIDIA Ampere se baseia nessas inovações, fornecendo até 20X mais operações flutuantes por segundo (FLOPS) para aplicativos de IA e até 2,5X mais FLOPS para aplicativos FP64 HPC.
A NVIDIA HGX A100 4-GPU oferece quase 80 teraFLOPS de desempenho FP64 para as cargas de trabalho HPC mais exigentes.
A NVIDIA HGX A100 8-GPU fornece 5 petaFLOPS de computação de aprendizado profundo FP16.
E a configuração HGX A100 16-GPU atinge impressionantes 10 petaFLOPS, criando a plataforma de servidor acelerado mais poderosa do mundo para IA e HPC.
AS VEZES PRECISAMOS VER PARA ACREDITAR, ASSISTA O VÍDEO CLICANDO ABAIXO
Largura de banda e escalabilidade potencializam análises de dados de alto desempenho
Os servidores HGX A100 fornecem o poder de computação necessário — junto com os primeiros 2 terabytes por segundo (TB/s) de largura de banda de memória do setor, junto com a escalabilidade do NVLink e NVSwitch — para lidar com análises de dados de alto desempenho e dar suporte a conjuntos de dados massivos.
Combinado com NVIDIA Mellanox Infiniband, o software Magnum IO, Spark 3.0 acelerado por GPU e NVIDIA RAPIDS, a plataforma de data center da NVIDIA agora pode acelerar essas cargas de trabalho massivas em níveis sem precedentes de desempenho e escala eficiente de data center.
Se você está buscando por hardware para:
High Performance Computing
Climate and Weather Modeling
Industrial, Logistic & Retail Automation
Visão Computacional
Conversational AI
Deep Learning
Drug Discovery
UAVs
Finance & Economics
UGVs
AI / Deep Learning Training
NetWork
Healthcare Business
Cloud & IA Data Center
Intelligence & Analytics
Rugged Notebooks
A Loja do Jangão é o lugar certo para você.
Por que escolher a Loja do Jangão?
Produtos de Qualidade Ouro: A loja trabalha apenas com marcas renomadas e produtos com garantia de qualidade.
Amplo catálogo: Encontre tudo o que você precisa em um só lugar, desde equipamentos para indústria, logística & retail, pesquisadores, professores, estudantes, entusiastas, agro, governo, exército, etc.
Atendimento especializado: Especialistas que irão apontar o produto ideal para sua necessidade.
Formas de pagamento facilitadas: A loja oferece diversas opções de pagamento, incluindo cartão de crédito com parcelamento em até 10x sem juros, boleto bancário, PIX, FINAME, e outros que dependem de bancos.
Entrega rápida e segura: Seus produtos são entregues com rapidez e segurança para todo o Brasil. Importamos do mundo inteiro. Temos experiência de +30 anos em comércio exterior.
É um prazer compartilhar com você nosso portfólio:
A Loja do Jangão é uma excelente opção para quem busca produtos de alta especificação e atendimento apontado para os últimos lançamentos das fábricas.
Observação: Para uma análise mais detalhada e personalizada, seria interessante conhecer um pouco mais sobre suas necessidades e preferências. Podemos até lhe ajudar em projetos com seus clientes.
E é com satisfação que nos colocamos à sua inteira disposição para futuras necessidades de orçamentos de produtos importados,mesmo que não estejam no nosso catálogo / website.
Já somos fornecedores de empresas do setor automobilístico, IA , Indústrias, Fundações, Universidades e Empresas dos Setores de Inteligência Artificial / Engenharia Ambiental / Energia , Consórcios de Vias, etc.